Collection子接口之Set
Set接口是Collection的子接口之一,它用来存储无序的、不可重复的元素。和Collection另一个子接口List不同,该子接口没有提供额外的方法。Set还有一个主要特点是:它存储的元素不能修改,只能新增和删除。
Set接口的主要实现类有:HashSet、TreeSet,另外HashSet还有一个子类LinkedHashSet。这三个类中,HashSet是开发中使用率最高的。
无序性理解
对一个HashSet实例遍历的结果是随机的,但是LinkedHashSet和TreeSet不一样。对LinkedHashSet和TreeSet遍历的结果是有一定规则的。
@Test
void test1 ()
{
HashSet set = new HashSet();
set.add(32);
set.add(35);
set.add(23);
set.add("abc");
System.out.println(set); // [32, 35, abc, 23]
}
@Test
void test2 ()
{
LinkedHashSet set = new LinkedHashSet();
set.add(32);
set.add(35);
set.add(23);
set.add("abc");
System.out.println(set); // [32, 35, 23, abc]
}
@Test
void test3 ()
{
TreeSet set = new TreeSet();
set.add(32);
set.add(35);
set.add(23);
set.add(48);
System.out.println(set); // [23, 32, 35, 48]
}Java中的Set无序性指的是:存储的数据在底层数组中并非按照数组索引的顺序添加,而是根据数据的哈希值决定的。
HashSet
特点:线程不安全、效率高、可以存取null值。HashSet采用hash算法来存储集合元素,它的添加、查找、删除效率都非常高。
HashSet hashSet = new HashSet();
// add
hashSet.add(32);
hashSet.add(12);
hashSet.add(122);
// contains
System.out.println(hashSet.contains(122));
// remove
hashSet.remove(122);遍历结果:对一个HashSet实例遍历的结果是随机的,这点和LinkedHashSet及HashSet不一样。
添加元素过程:
当向 HashSet 集合中存入一个元素时,HashSet 会调用该对象的 hashCode() 方法来得到该对象的 hashCode 值,然后根据 hashCode 值,通过某散列算法决定该对象在 HashSet 底层数组中的存储位置。(这个散列算法会与底层数组的长度相计算得到在数组中的下标,并且这种散列算法计算还尽可能保证能均匀存储元素,越是散列分布,该散列算法设计的越好)
情况一:获取到存储位置后,判断该位置上是否已经有元素了:若没有,则直接将新元素添加到该位置上。
情况二:若该存储位置已经有元素了,那么依次和该位置链上所有元素比较(通过equals),如果都不相同,则将新元素添加到该链上。
情况三:若该存储位置已经有元素了,且和链上的某个元素的通过equals比较,返回值为true,那么则添加失败。
HashSet数据结构如下图所示:
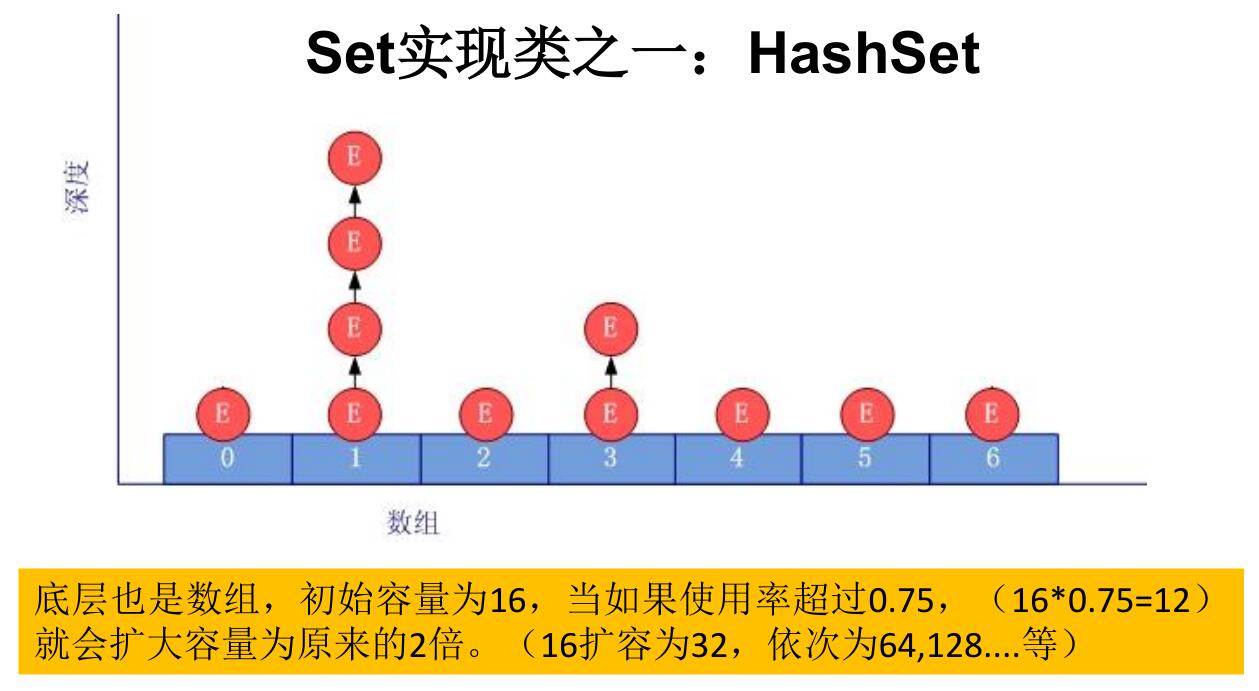
从上面HashSet添加元素的过程可以得出:向Set(主要指:HashSet、LinkedHashSet)中添加的数据,其所在的类一定要重写hashCode()和equals()。equals与hashCode的定义必须相容,如果x.equals(y)返回true,那么x.hashCode就必须与y.hashCode返回相同的值。
LinkedHashSet
LinkedHashSet作为HashSet的子类,在添加数据的同时,每个数据还维护了两个引用,记录此数据前一个数据和后一个数据。这样就会导致它存储的元素结构要更加复杂,会降低它的存储效率。但带来的好处是,遍历的效率会优于HashSet。

TreeSet
TreeSet 是 SortedSet 接口的实现类,TreeSet 可以确保集合元素处于排序状态。它底层是使用(二叉树)红黑数结构
- 向TreeSet中添加的数据,要求是相同类的对象。
- 两种排序方式:自然排序(实现Comparable接口) 和 定制排序(Comparator)
- 自然排序中,比较两个对象是否相同的标准为:compareTo()返回0.不再是equals().
- 定制排序中,比较两个对象是否相同的标准为:compare()返回0.不再是equals().
// 自然排序,按薪资
TreeSet<Employee> employees = new TreeSet<>();
employees.add(new Employee("james", 36, 4000));
employees.add(new Employee("pual", 35, 4100));
employees.add(new Employee("durant", 32, 3800));
employees.add(new Employee("curry", 32, 4150));
System.out.println(employees);
// 定制排序,按年龄、姓名
TreeSet<Employee> employees2 = new TreeSet<>(
Comparator.comparing(Employee::getAge)
.thenComparing(Employee::getName)
);
employees2.add(new Employee("james", 36, 4000));
employees2.add(new Employee("pual", 35, 4100));
employees2.add(new Employee("durant", 32, 3800));
employees2.add(new Employee("curry", 32, 4150));
System.out.println(employees2);Set的一个应用——去除List中重复的元素。
void test1 ()
{
ArrayList arrayList = new ArrayList();
arrayList.add(1);
arrayList.add(1);
arrayList.add(13);
arrayList.add(133);
arrayList.add(133);
System.out.println(ListUniqued(arrayList));
}
public static List ListUniqued (List list)
{
HashSet hashSet = new HashSet(list);
return new ArrayList(hashSet);
}